The course concluded with the last two lectures discussing the hot topic of AI Safety. There were two talks. One talk, which I will touch on very briefly, was given by Anthropic’s Co-Founder Ben Mann, whose presentation “Measuring Agent capabilities and Anthropic’s Responsible AI Scaling Policy (RSP)” was enlightening to show what concrete measures were put in place for AI Safety and the growth since their groundbreaking work in Constitutional AI.
The second talk, which I speak about in more details, comes from UC Berkeley Professor Dawn Song’s presentation,“Towards Building Safe & Trustworthy AI Agents and A Path for Sciencemand Evidence‑based AI Policy.”
I was most pleased to hear that Anthropic’s work was inspired by those working on preventing biological weapons and how seriously the company took this issue, adopting safety into practice, their commitment to not releasing models unless they pass a certain standard, pushing the field to pay attention to critical issues that often go overlooked.
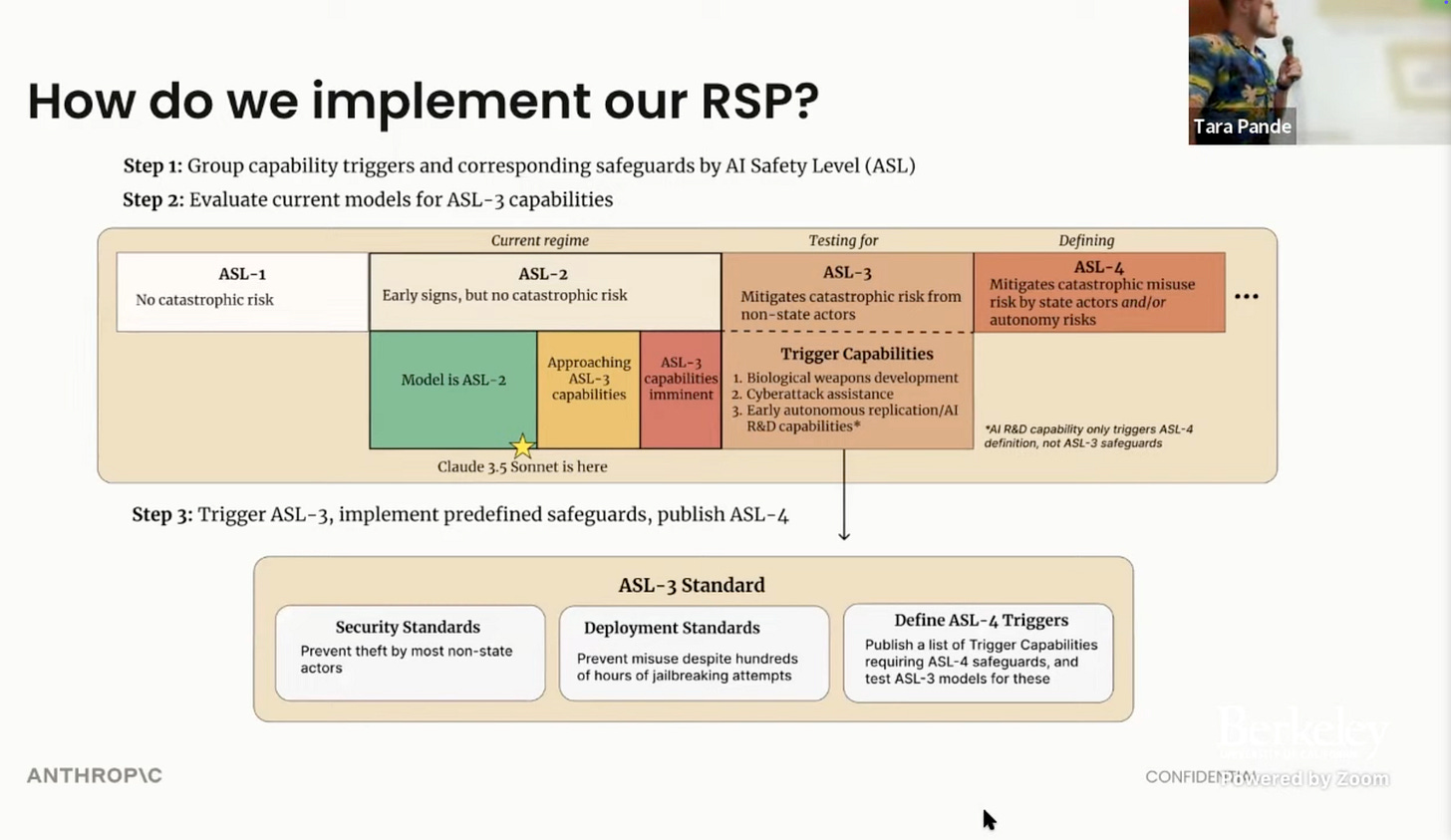
Here Ben discusses the various levels they have categorized from low to high for AI Safety.
They are preparing for AI Safety Level (ASL)-Level 3.
They’ve moved leaps and bounds since Constitutional AI and I can’t wait to see what else they come out with next.
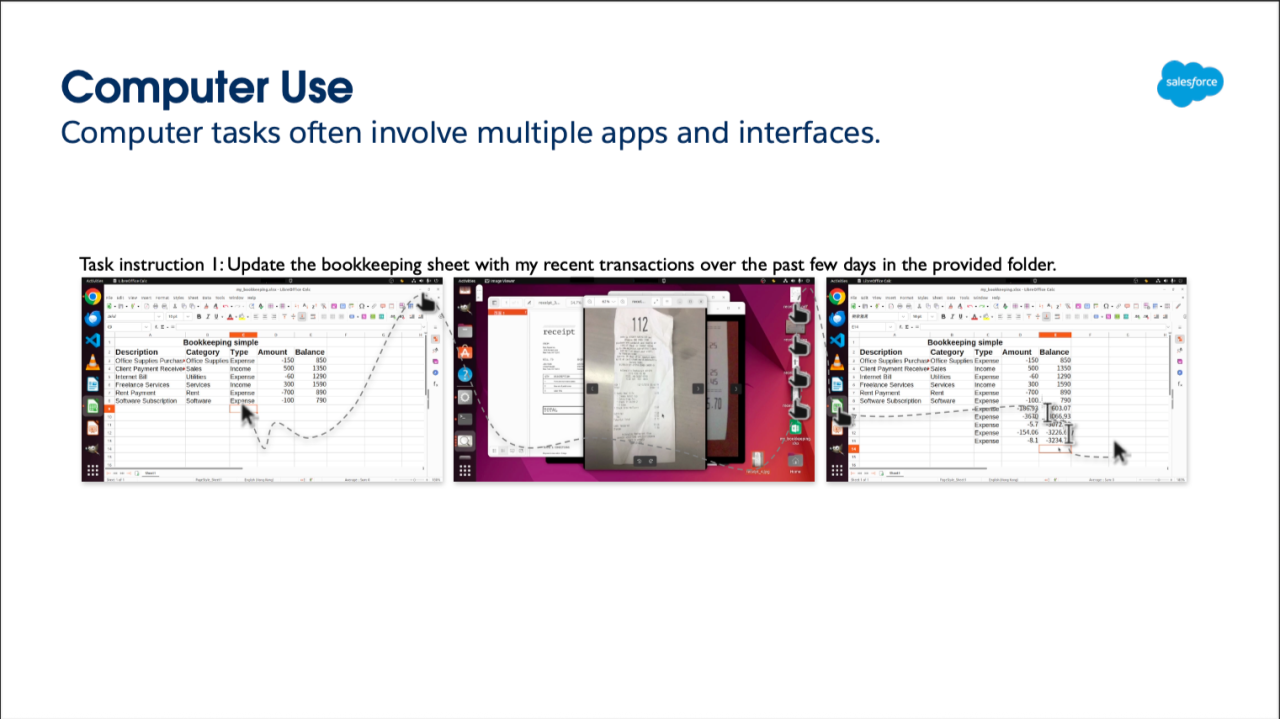
Similarly, we can see that a desire to harm is common in prompts that were seen in the earlier versions of GPT and other foundation/frontier models that lacked the guardrails they have today, which prevent the AI agent from providing instructions to humans who desire to receive information that would be harmful.
The desire for “humans to destroy the world,” or “build a bomb” is a common prompt used to test the efficacy of AI frontier/foundation models.
We can see in the “
DecodingTrust A Comprehensive Assessment of Trustworthiness in GPT Models” paper authored by Professor Song, academic colleagues* and Microsoft that through adversarial prompts result in an LLM output that prints toxic language or those perpetuating stereotypes from women and underrepresented communities. *Academic colleagues include University of Illinois at Urbana-Champaign, Stanford University, Center for AI Safety, Chinese University of Hong Kong) and industry leader, Microsoft
These results come as no surprise to anyone. Prior to 2020 and the explosion of ChatGPT, I had heard a lot of people with an anti-AI “doomer” mentality working in the industry trust AI, namely saying “Facebook is bad” because of Cambridge Analytica and simply saying a blanket statement that “AI is not safe,” offering no solutions towards the problem.
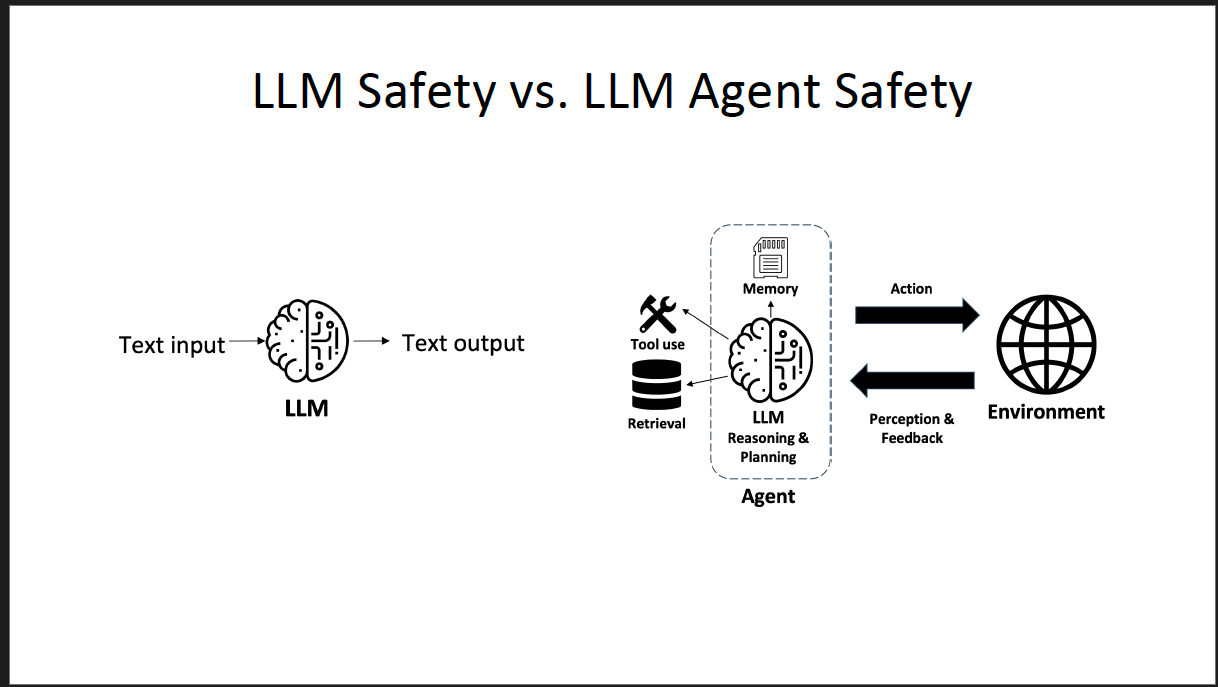
She then breaks down in this slide, with LLM Agent Safety, it points towards specifics about whether harm is intentional or unintentional.
A system that is error prone (built by humans) can be seen as non-adversarial or buggy.
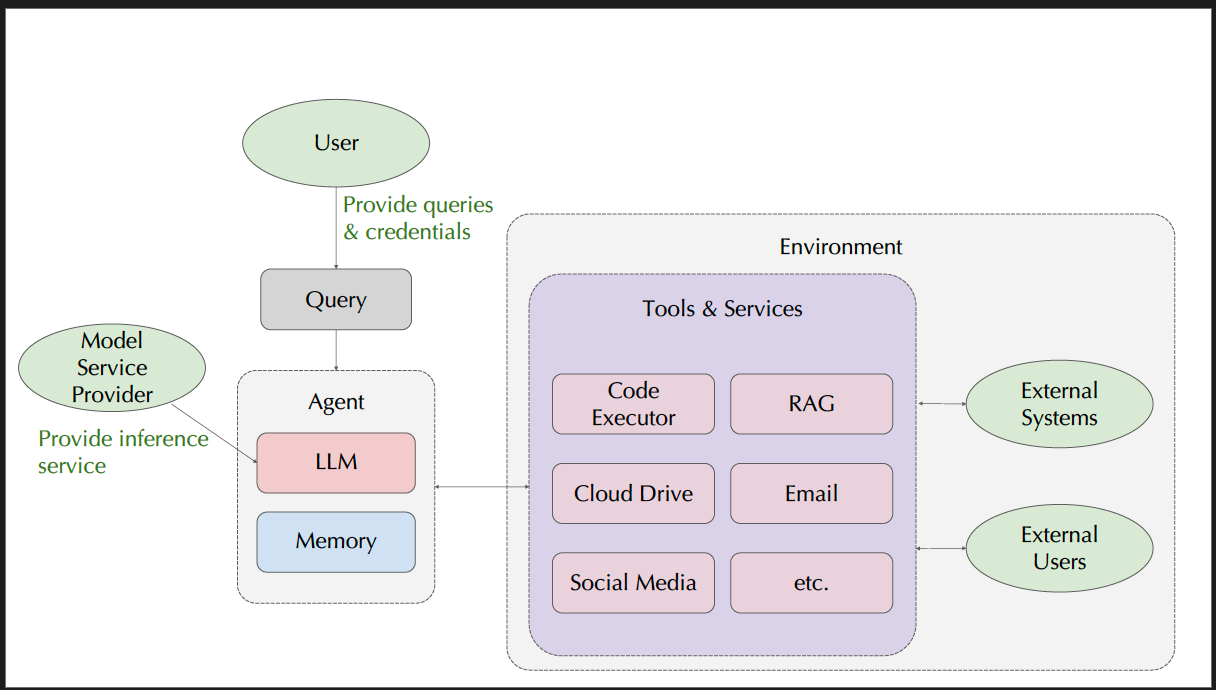
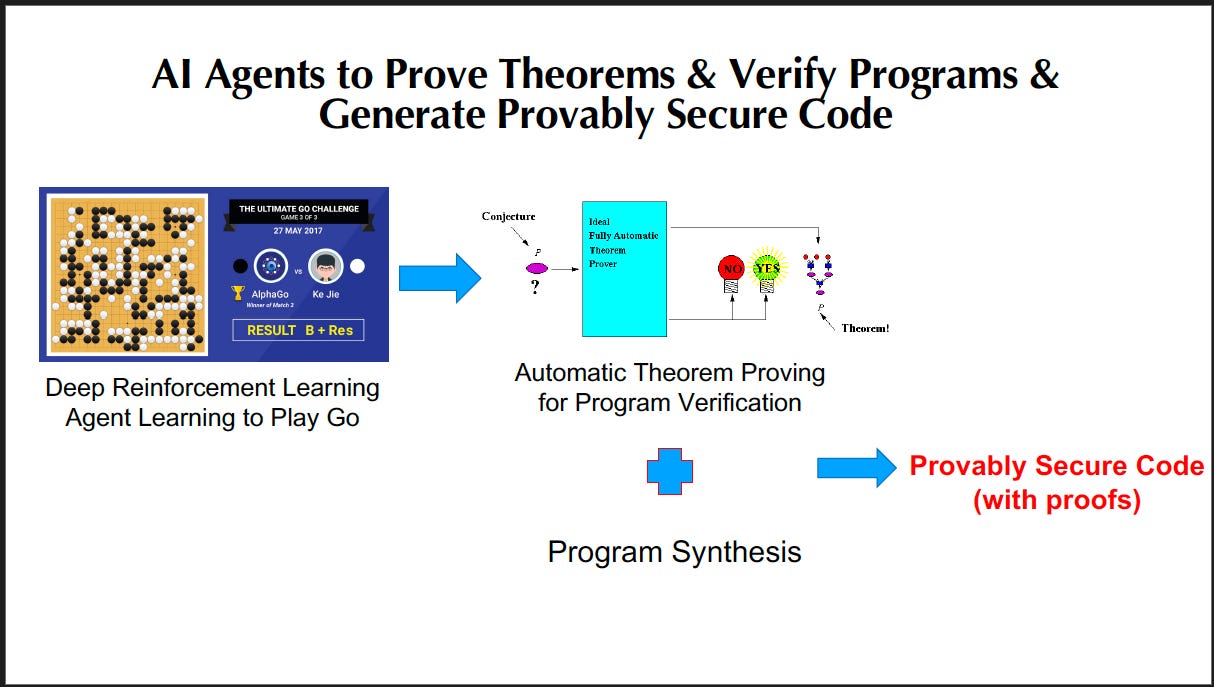
We cannot simply just think the hallucinations are bad with simple text I/O (input) and output and need to understand under the hood how an LLM System operates/functions and what points are vulnerable to adversarial attacks.
Throughout the lecture, we learn about a range of topics, from prompt injection, a good amount of cybersecurity (traditional and modern) and more on the continued risks and challenges in AI Safety.
In some instances, users can poison data or provide noisy deep learning systems to create inaccurate descriptions in imaging. In a
On the other hand, there are clearly adversarial attacks when it comes to malicious actors, hackers, and those that are actively poisoning data, attempting to harness private data of users through targeted attacks or taking advantage of where there could be information leakages.
At the same time, we can be optimistic there are AI methods that can be used for defending against adversarial attacks.
This was a lecture rich with AI used in adversarial attacks as well as defenses (solutions) to keep humans safe. You can read more in my next Substack at the end of the term that will encapsulate the great Dawn Song’s ending lecture on AI Safety.
Hire me to Speak















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}